Context
Prompt
How might we develop a training dataset for machine summarization (and cope with the worst year in modern human history)?
Background
The project started with a seemingly simple goal: teaching Tensorflow to write haikus about current events. Since poetry is subjective, there aren’t straightforward objective functions to quantify good haikus, so we’d need some actual haikus as training data (i.e. self-supervised is out).
Challenges
- 2020 had no shortage of news to seed moody poetry, but at the time no such news → haiku datasets existed.
- There are a number of ways to gather up pre-written text in the shape of a haiku (5,7 and 5 syllables), but these would surely lack the spirit of a real haiku (much less the kireji).
Approach
Insights
When you need repetitive and weird things done by humans on the internet, there’s only one place to turn: Mechanical Turk.

Design & Build
- Developed a data pipeline to extract top posts from popular news-related subreddits, scrape the referenced URL to develop a prompt, submit custom “human intelligence tasks” (HITs) to Mechanical Turk, then pull results, clean and store them. (Technology was Google Cloud Run, Firestore, Clojure)
- Developed a supplemental database of word word syllables that don’t appear in canonical sources like CMU’s Pronunciation Dictionary
- Automated the review process for the majority of submissions, built tooling to facilitate quick manual review of exceptions
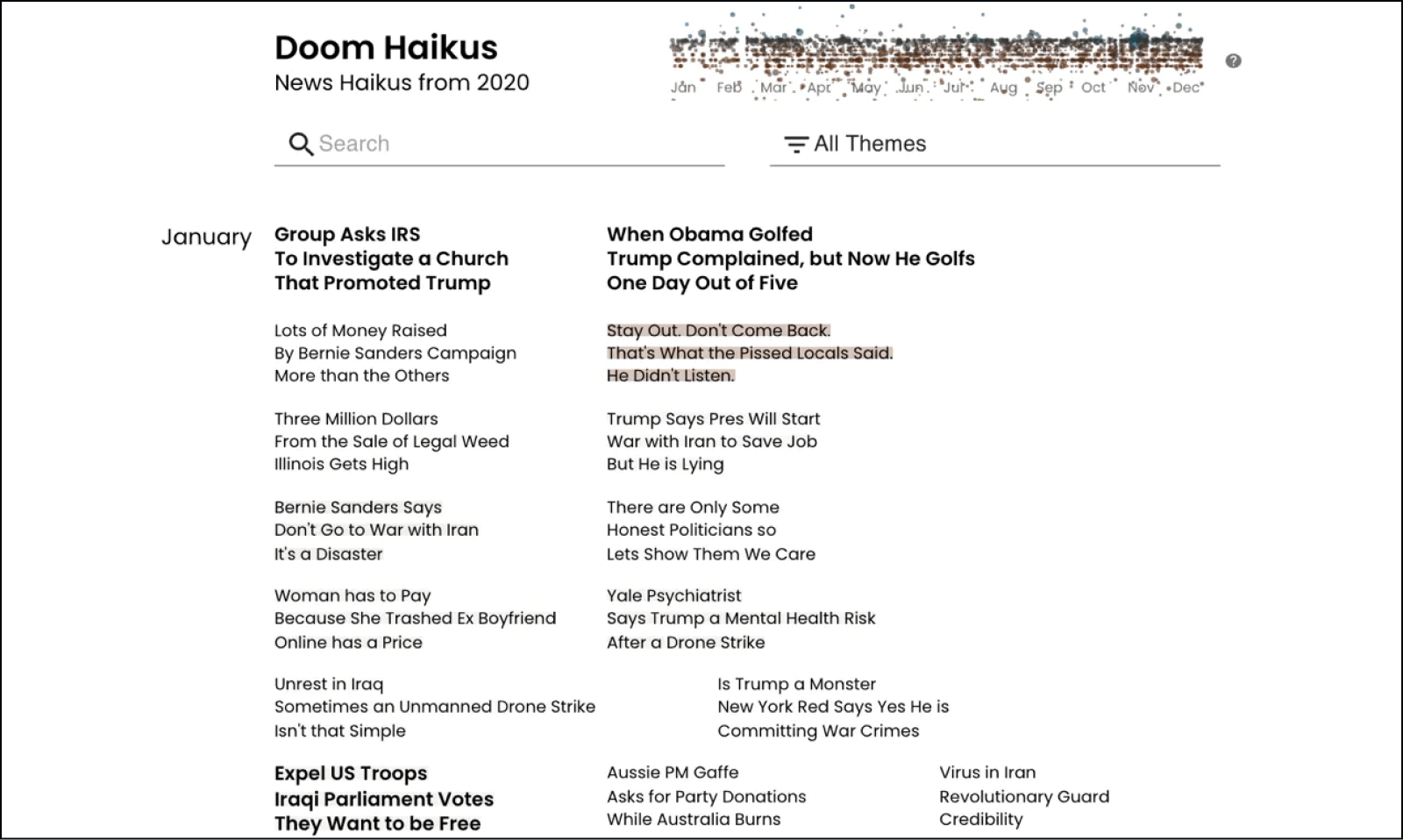
- Data Product Prototyping. Developed a javascript prototype app to explore haikus, combining instant, client-side search with a custom canvas data visualization, allowing users to read individual haikus but also get a sense for overall news trends. (Technology was React, D3, Canvas)
Results
- From March - December 2020, ~2,000 people on Mechanica Turk submitted ~2,700 hand-written haikus about the news events of the day.
- Launched https://doomhaikus.3iap.com in December 2020.
- Project / dataset were featured on Data Is Plural, Nightingale, Product Hunt (home page), Boing Boing and AVClub.
